
Core Architecture Principles
Mastering Scalability: A Deep Dive into Vertical vs. Horizontal Scaling for Distributed Systems
Executive Summary
This comprehensive architectural review dissects the fundamental strategies of vertical and horizontal scaling, providing senior engineering leadership with a nuanced understanding of their implications for large-scale distributed systems. We explore the inherent trade-offs, operational complexities, and architectural paradigms required to build resilient, performant, and cost-effective infrastructure capable of handling petabytes of data and millions of concurrent users. The document emphasizes the critical shift from monolithic, vertically scaled applications to horizontally distributed microservices, detailing the essential components, data consistency challenges, and advanced techniques necessary for achieving true elasticity and high availability in modern cloud environments.
Background
In the relentless pursuit of performance and availability, system architects constantly grapple with the challenge of scaling. As user bases grow and data volumes explode, the initial simplicity of a single-server application quickly gives way to complex distributed architectures. Understanding the foundational differences between vertical and horizontal scaling is paramount for making informed design decisions that impact an organization's ability to innovate, operate efficiently, and meet ever-increasing demand.
The Inevitable Growth Trajectory
Every successful application experiences growth. This growth manifests in several key dimensions:
- Increased Request Volume: More users, more API calls, higher transaction rates
- Expanded Data Storage: Larger datasets, more historical information, richer user profiles
- Complex Processing: More sophisticated algorithms, real-time analytics, machine learning inferences
Initially, a single, powerful server might suffice. However, this approach has inherent limitations that quickly become bottlenecks.
System Requirements and Scale Estimates
Consider a modern web service, such as a social media platform or an e-commerce giant, aiming for:
- Daily Active Users (DAU): Tens of millions to hundreds of millions
- Peak Requests Per Second (RPS): Hundreds of thousands to millions
- Data Storage: Petabytes of user-generated content, transaction logs, and analytical data
- Latency: Sub-100ms for critical read operations, sub-500ms for writes
- Availability: Four nines (99.99%) or five nines (99.999%) for core services
- Fault Tolerance: Ability to withstand node failures, zone outages, and even regional disasters
These ambitious targets necessitate a scaling strategy that goes beyond simply upgrading hardware.
Core Concepts
At the heart of any scalable system lies a clear understanding of how resources are added and managed. Vertical and horizontal scaling represent two distinct philosophies for achieving this.
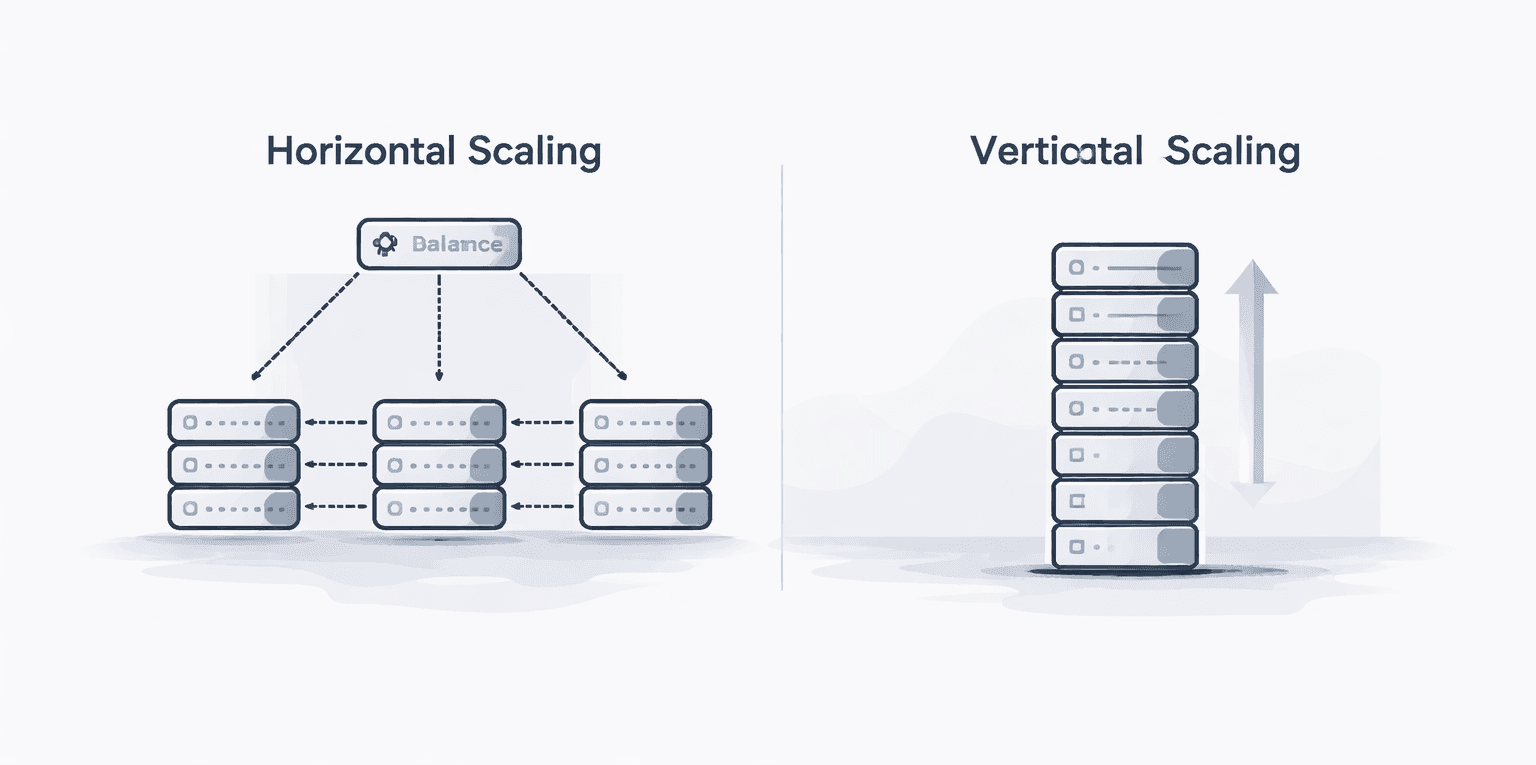
Vertical Scaling (Scaling Up)
Vertical scaling, often referred to as scaling up, involves enhancing the capabilities of a single server. This means adding more:
- CPU Cores
- RAM
- Faster Storage
- Network Interfaces
Advantages
- Simplicity: Easier to manage, as there's only one machine
- Lower Latency (Initially): No network overhead within the same machine
- Easier Consistency: Simpler data consistency
Disadvantages
- Hardware Limits
- Single Point of Failure (SPOF)
- Downtime for Upgrades
- Cost Inefficiency
Horizontal Scaling (Scaling Out)
Horizontal scaling, or scaling out, involves distributing the workload across multiple machines.
Key Components
- Load Balancers
- Stateless Services
- Distributed Databases/Storage
- Message Queues
- Service Discovery
Advantages
- Near-Infinite Scalability
- High Availability
- Cost-Effectiveness
- Fault Isolation
- Zero-Downtime Deployments
Disadvantages
- Increased Complexity
- Distributed System Challenges
- Operational Overhead
Data Models and Database Choices
Choosing the right database is critical for horizontal scaling.
- Relational Databases: Use read replicas and sharding
- NoSQL Databases: Designed for horizontal scaling with flexible consistency models
Architecture Deep Dive
The Monolithic Starting Point
- Web/Application Server
- Database
- Cache
Simple but suffers from:
- Single point of failure
- Resource contention
Deconstructing the Monolith
1. Load Balancing Layer
- Layer 4 vs Layer 7
- Algorithms: Round-robin, least connections, IP hash
- Health checks
2. Stateless Application Services
- No local session storage
- External session stores (Redis, etc.)
3. Distributed Data Stores
- Sharding: Hash, range, directory-based
- Replication: Leader-follower, multi-leader
- Consistency Models: Strong, eventual, causal
4. Caching Layer
- Redis / Memcached
- Cache invalidation strategies (TTL, write-through, etc.)
5. Message Queues
- Kafka, RabbitMQ, SQS
- Enables decoupling and buffering
6. Service Discovery
- Consul, etcd, ZooKeeper
How It Works
Read Flow
- Client sends request
- DNS/CDN resolves
- Load balancer routes
- Service checks cache
- Cache miss → DB query
- Cache populated
- Response returned
Write Flow
- Request hits service
- Validation
- Write to DB shard
- Cache invalidation/update
- Event published to queue
- Response returned
Implementation Guide
Stateless API Example (Python)
Async Processing Example (Go + Kafka)
Performance and Scalability
Caching Strategies
- Distributed cache
- CDN
- Eviction policies (LRU, LFU, FIFO)
Sharding
- Key selection is critical
- Avoid hotspots
- Resharding complexity
Load Balancing
- Layer 4 vs Layer 7
- Algorithms: round robin, least connections
Optimization
- Async processing
- Connection pooling
- Batching
- Compression
- Efficient protocols
Auto-Scaling
- Dynamic scaling based on metrics
Security and Reliability
Fault Tolerance
- Redundancy
- Circuit breakers
- Bulkheads
- Retries with backoff
- Idempotency
CAP Theorem
- C: Consistency
- A: Availability
- P: Partition tolerance
Trade-offs:
- CP systems
- AP systems
Data Replication
- Leader-follower
- Multi-leader
- Quorum-based
Leader Election
- Raft, Paxos
Security
- Network segmentation
- mTLS / JWT
- Encryption (in transit + at rest)
- Secrets management
Common Pitfalls
- Ignoring CAP theorem
- Stateful services
- Bad shard key
- N+1 queries
- Cascading failures
- Distributed transaction complexity
- Over-engineering
- Lack of observability
- Network bottlenecks
- Clock skew
Real-World Use Cases
Netflix
- Microservices
- Cassandra, DynamoDB
- Chaos engineering
Amazon (DynamoDB)
- AP system
- Consistent hashing
- Quorum reads/writes
Google (Spanner)
- Strong consistency
- TrueTime
- Global transactions
Future Trends
- Serverless (FaaS)
- Edge computing
- WebAssembly
- AI-driven auto-scaling
- Observability-driven systems
- Data mesh
- Next-gen distributed databases
Key Takeaways
- Embrace Statelessness
- Data is the Hardest Part
- Decouple with Async Communication
- Prioritize Observability
- Design for Failure